Die Versorgung betrieblicher Entscheidungsträger mit validen und aktuellen Informationen zur Wahrnehmung der Führungs-, Steuerungs- und Kontrollaufgaben ist zu einer der wichtigsten Herausforderungen für die Wirtschaftsinformatik geworden. Unter wechselnden Schlagworten wurden Konzepte zur Informationsversorgung des Managements propagiert, deren Einsatztauglichkeit aber häufig hinter den Erwartungen zurückblieb. Dennoch haben sich seit den 1990er Jahren in fast allen Unternehmungen Data-Warehouse-Lösungen durchsetzen können, da diese nachweislich zu einer erhöhten Qualität und Aktualität der Informationsbereitstellung für Fach- und Führungskräfte beitragen.
Einordnung
Die Informationsbereitstellung ist und bleibt ein wesentlicher Gesichtspunkt von Managementunterstützungs- bzw. Business-Intelligence-Systemen. Große Potenziale entfaltet die Sammlung, Verdichtung und Selektion entscheidungsrelevanter Informationen insbesondere auf Basis einer konsistenten unternehmungsweiten Datenhaltung.
An dieser Stelle setzt das Data-Warehouse-Konzept an und fordert den Aufbau einer zentralen und von den Vorsystemen getrennten Datenbasis zur Unterstützung dispositiver Aufgaben [Gluchowski, Gabriel, Dittmar 2008, S. 118; Baars, Kemper 2021, S. 19]. Im Idealfall soll eine derartige Datenbasis unternehmens- bzw. konzernweit ausgerichtet sein und das Informationsbedürfnis verschiedenster Anwendergruppen abdecken. Aus technischen Gründen erweist es sich als sinnvoll, ein derartiges zentrales Data Warehouse (DW) von den datenliefernden Vorsystemen zu entkoppeln und auf einer separaten Plattform zu betreiben, was teilweise sogar als konstituierendes Merkmal für Data Warehouse-Lösungen gewertet wird [Hahne 2014, S. 2]. Eine Entkopplung führt einerseits zu einer Entlastung der operativen Systeme und eröffnet andererseits die Option, das analyseorientierte System auf die Belange von Auswertungen und Berichten hin zu optimieren [Gluchowski, Gabriel, Dittmar 2008, S. 118].
Die erstmalige Verwendung der Begrifflichkeit kann bis in die späten 1980er Jahre zurückverfolgt werden, als Devlin und Murphy das Data Warehouse als zentrale Datensammelstelle skizzieren, die den Nutzer von technischen Details der Datenintegration entlastet, damit er sich auf die Verwendung der aufbereiteten Inhalte konzentrieren kann [Devlin, Murphy 1988, S.61].
Sehr zur Popularität des Data-Warehouse-Konzeptes hat William Inmon beigetragen, der die vier idealtypischen Merkmale Themenorientierung, Vereinheitlichung, Zeitorientierung und Beständigkeit formuliert hat, die bis heute weitgehend Gültigkeit aufweisen [Inmon 2005]. Mit dieser inhaltlichen Ausrichtung einer Data-Warehouse-Lösung ist folglich die zugehörige Aufgabenstellung festgelegt, themenorientierte und integrierte (i. S. v. vereinheitlichte) Informationen über lange Zeiträume und mit Zeitbezug zur Unterstützung von Entscheidern aus unterschiedlichen Quellen periodisch zu sammeln, nutzungsbezogen aufzubereiten und bedarfsgerecht zur Verfügung zu stellen [Gluchowski, Gabriel, Dittmar 2008, S. 121; Kemper, Baars, Kemper 2021, S. 20].
Gestaltung einer Data Warehouse-Lösung
Beim Aufbau eines Data Warehouse-Konzeptes sind sowohl betriebswirtschaftlich-organisatorische als auch technische Gestaltungsaspekte sorgfältig zu durchdenken. Aus betriebswirtschaftlich-organisatorischer Sicht ist zu überlegen, welche Informationen auf welchen Verdichtungsstufen im Datenspeicher abgelegt werden müssen und welchen Mitarbeitern diese zugänglich gemacht werden sollen. Zudem ist zu klären, was konkret unter einzelnen Begriffen zu verstehen ist bzw. woraus sich die einzelnen Größen zusammensetzen, was sie repräsentieren und wie sie ermittelt werden [Gluchowski 2016, S. 230 – 232].
Daneben muss ebenfalls ein tragfähiges technisches Realisationskonzept mit dem Ziel erarbeitet werden, die atomaren Daten aus den vielfältigen und heterogenen operativen Vorsystemen systematisch zusammenzuführen. Aus diesem Grund sind periodisch oder ad-hoc Verbindungen aufzubauen, um die relevanten Daten zu extrahieren. Durch vielfältige Aufbereitungsmechanismen werden diese gesäubert und entsprechend den Anforderungen strukturiert abgelegt. Die Integration der Daten in einem System führt dazu, dass ein gleichartiger Zugriff auf ein sehr breites inhaltliches Spektrum ermöglicht wird. Da im Idealfall alle Managementanwendungen eines Unternehmens mit diesen Daten arbeiten, gibt es nur eine „Version der Wahrheit“ [Gluchowski, Gabriel, Dittmar 2008, S. 124], d. h. dass in unterschiedlichen Berichten und Auswertungen auch abteilungsübergreifend keine abweichenden Zahlen vorkommen können.
Architektur und Komponenten
Wurde am Anfang der Diskussion um das Data-Warehouse-Konzept noch vehement um die richtige Anordnung einzelner Komponenten gerungen, so hat sich im Laufe der Zeit die Hub-and-Spoke-Architektur als geeignete Form des Aufbaus einer entscheidungsorientierten IT-Landschaft etabliert [Hahne 2014, S. 10f.]. Die gewählte Begrifflichkeit ist darauf zurückzuführen, dass die Anordnung der Komponenten an eine Naben-Speichen-Kombination erinnert.
Der Datenfluss führt ausgehend von den operativen und externen Informationssystemen, die als Lieferanten für das Rohdatenmaterial dienen, über die eingesetzten Komponenten für die Extraktion, Transformation und das Laden von Daten (ETL) zunächst bis zum Enterprise (oder Core) Data Warehouse. Hier finden sich aufbereitete und aggregierte Daten (beispielsweise auf Tagesbasis) aus allen Unternehmensbereichen und mit langer, meist über mehrere Jahre reichende Historie. Das gespeicherte Datenvolumen im Core Data Warehouse erweist sich in der Regel als sehr umfangreich und kann Größenordnungen bis in den hohen Terabyte-Bereich annehmen.
Bei einem derart großen Datenvolumen bereiten vor allem interaktive und ggf. multidimensionale Sichtweisen auf den verfügbaren Datenbestand mit ausgeprägter Navigationsfunktionalität erhebliche Probleme. Schließlich sind entsprechend den OLAP-Forderungen beliebigen Rotationen und Schnittbildungen nebst Analysefunktionalitäten anzubieten. Aus diesem Grund werden Datenextrakte zur weiteren Verarbeitung gebildet, die sich als personen-, anwendungs-, funktionsbereichs- oder problemspezifische Segmente des zentralen Data Warehouse-Datenbestandes verstehen und als Data Marts [Baars, Kemper 2021, S. 22] bezeichnen lassen.
Beim Zusammenspiel zwischen einem Data Warehouse und den zugehörigen Data Marts sind unterschiedliche Grundformen voneinander abgrenzbar. Sehr häufig setzen Data Marts auf dem zentralen Data Warehouse auf und speichern Teilextrakte des Gesamtdatenbestandes nochmals separat in physischer Form ab.
Abbildung 1 visualisiert die unterschiedlichen Speicherkomponenten einer Data Warehouse-Lösung nochmals mitsamt den zugehörigen Datenflüssen.
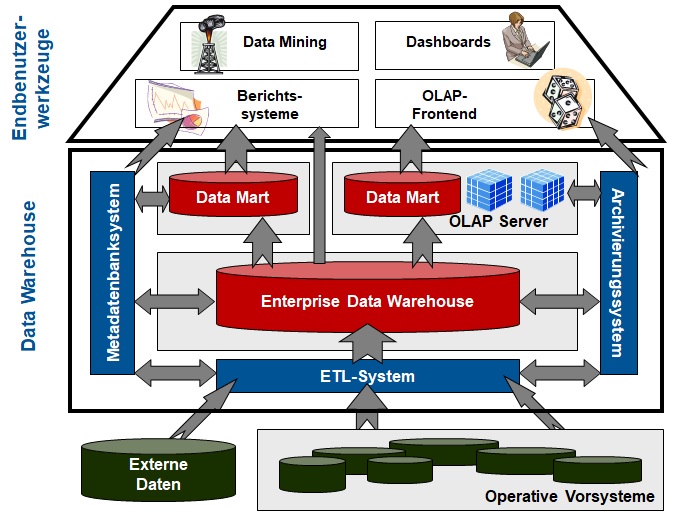
Abb. 1: Hub-and-Spoke-Architektur
Neben den Speicherkomponenten für die Problemdaten weist eine Data Warehouse-Architektur auch ein Archivierungssystem auf, das sowohl der Datenarchivierung als auch der Datensicherung dient. Die Datensicherung wird zur Wiederherstellung der Inhalte eines Data Warehouses im Falle von Programm- oder Systemfehlern benötigt. Die zu speichernden Datenvolumina in einem Data Warehouse können im Laufe der Nutzungszeit einen erheblichen Umfang erreichen. Um das Volumen in erträglichen Grenzen zu halten, werden Archivierungssysteme eingesetzt, die atomare wie verdichtete Daten aus der Data-Warehouse-Datenbank entfernen, ohne dass diese für spätere Analysen verloren gehen. Technologisch erfolgt dabei eine Auslagerung eines Teils der Daten aus der Data-Warehouse-Datenbank in langsamere Datenträger, auf die entweder direkt zugegriffen werden kann oder aus denen sich der ursprüngliche Datenbestand jederzeit regenerieren lässt.
Neben den entscheidungsorientierten Daten enthält ein Data Warehouse auch Metadaten, die in einem Metadatenbanksystem verwaltet werden. Im Idealfall handelt sich dabei nicht nur um rein technische Angaben, die neben ihrer Informationsfunktion auch zur Steuerung des Data-Warehouse-Betriebs dienen. Vielmehr werden im Metadatenbanksystem auch betriebswirtschaftliche Angaben abgelegt, die dem Endanwender dabei helfen, Analyseanwendungen effektiver einzusetzen und deren Ergebnisse zu interpretieren oder die für ihn relevanten Daten zu finden. In diese Kategorie der semantischen Metadaten fallen beispielsweise Dokumentationen zu vordefinierten Anfragen und Berichten sowie die Erläuterung von Fachbegriffen und Terminologien.
Allerdings ist darauf hinzuweisen, dass das vorgestellte Hub-and-Spoke-Architekturkonzept nur eine mögliche Architekturvariante darstellt. In der praktischen Ausgestaltung finden sich auch Lösungen, die davon abweichen und beispielsweise ohne Data Marts oder mit unabhängigen Data Marts operieren [Baars, Kemper 2021, S. 22; Seiter 2019, S. 83].
Neben der klassischen Hub-and-Spoke-Architektur hat sich in den letzten Jahren in immer stärkeren Maße eine logische Aufteilung des DW-Datenbestandes in Schichten ergeben, die in ihrer Gesamtheit heute als Data-Warehouse-Schichtenarchitektur bezeichnet wird [Hahne 2014, S. 16 – 23]. Auch wenn die einzelnen Ebenen teilweise unterschiedlich benannt sind und auch die Anzahl der Schichten variieren kann, erfolgt hier die Vorstellung einer idealtypischen Architektur mit insgesamt vier Datenschichten bzw. Layer.
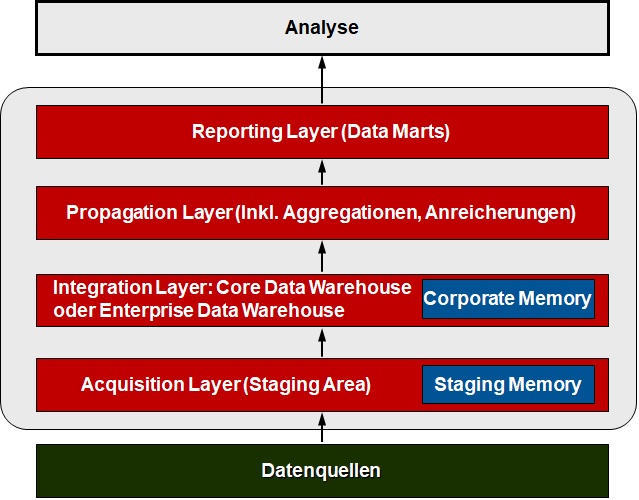
Abb. 2: DW-Schichtenarchitektur
Der Acquisition Layer dient der Aufnahme untransformierter Rohdaten aus internen und externen Datenquellen. Bereits im Kontext der Hub-and-Spoke-Architektur war ein derartiger Datenbereich unter der Bezeichnung Staging Area gebräuchlich. Vor allem dann, wenn die angelieferten Rohdaten als Textdateien formatiert sind, wird hier auch von einer Landing Zone gesprochen. Im Falle einer dauerhaften Ablage der Rohdaten zur möglichen späteren Verwendung der Extraktionshistorie erfolgt die Bezeichnung Staging Memory.
Der Integration Layer entspricht dem Enterprise oder Core Data Warehouse klassischer Prägung und bildet mit aufbereiteten Daten das Ziel der Transformations- und Harmonisierungsprozesse in ihrer vollständigen Historie. Im Gegensatz zu früheren Lösungen finden sich die Daten hier heutzutage oftmals in der größtmöglichen Detailierung, d.h. bis auf die Belegebene der datenliefernden Vorsysteme. Das gesamte gespeicherte Datenvolumen kann in dieser Komponente bis in den dreistelligen Terabyte-Bereich und darüber hinaus anwachsen, zumal die Daten über einen mehrjährigen Zeitraum vorgehalten werden. Der Integration Layer vereinigt durch die Bereitstellung der gesamten relevanten Unternehmensdaten in detaillierter und integrierter Form damit sowohl eine Sammel- und Integrationsfunktion als auch als Hub für nachgelagerte Schichten eine Distributionsfunktion in sich.
Der Propagation Layer implementiert einheitliche Business-Logiken bzw. Business-Rules, indem eine zentrale Ermittlung abgeleiteter Merkmale und Kennzahlen an einer Stelle erfolgt. Durch die zentralisierte Ableitung wird vermieden, dass unterschiedliche Berechnungsvorschriften auf dem Weg zu den nachgelagerten Data Marts zur Anwendung gelangen. Je nach Anwendungsfall kann auf diese Schicht auch verzichtet werden.
Der Reporting Layer stellt Daten für den Fachbereich aufbereitet entsprechend der betriebswirtschaftlichen Aufgabenstellungen zur Verfügung. Im Allgemeinen erfolgt die Speicherung dieser Daten in unterschiedlichen, aufgabenbezogenen Data Marts und dort mit multidimensionalen Datenstrukturen, wobei in immer stärkeren Maße auch die Belange von Self Service Beachtung finden. Aufgrund der ausgeprägten Volatilität der Anforderungen aus den Fachbereichen (Business Requirements) muss eine gute Anpassbarkeit durch hohe Agilität gewährleistet sein.
Zusammenfassend ist damit unter einem Data Warehouse ein unternehmensweites Konzept zu verstehen, das als logisch zentraler Speicher eine einheitliche und konsistente Datenbasis für die vielfältigen dispositiven Anwendungen bietet und losgelöst von den operativen Datenbanken betrieben wird.
Literatur
Gluchowski, Peter; Gabriel, Roland; Dittmar, Carsten: Management Support Systeme und Business Intelligence, Computergestützte Informationssysteme für Führungskräfte und Entscheidungsträger. 2. Auflage. Berlin u. a.: Springer, 2008.
Gluchowski, Peter: Entwicklungstendenzen bei Analytischen Informationssysteme, in: Chamoni, Peter; Gluchowski, Peter (Hrsg.): Analytische Informationssysteme. Business Intelligence-Technologien und -Anwendungen, Berlin u. a.: Springer, 2016, S. 225 – 238.
Hahne, Michael: Modellierung von Business-Intelligence-Systemen, Heidelberg: dpunkt, 2014.
Inmon, William H.: Building the Data Warehouse. 4. Auflage. New York: Wiley, 2005.
Baars, Henning; Kemper, Hans-Georg: Business Intelligence & Analytics – Grundlagen und praktische Anwendungen, Ansätze der IT-basierten Entscheidungsunterstützung, 4. Auflage, Wiesbaden: Springer Vieweg, 2021.
Seiter, Mischa: Business Analytics. Effektive Nutzung fortschrittlicher Algorithmen zur Unternehmenssteuerung, 2. Aufl., München: Vahlen, 2019.